


Extracts are great.
Extracts are awful
Two common thoughts on extracts are they are both good and bad. The good thing about extracts from the end user of a published dashboard is that it means any interaction with the dashboard is going to be nice and zippy. It should load quickly and any filtering, actions etc should be nice and fluid. Thats because we are no longer having to do the round trip to the database. Normally with a published workbook that uses a live data connection Tableau Server has quite a bit to do
First it has to send the query to the underlying database where-ever that may be.
The query is run on the database and takes time to run. If its a complex query, or if its retrieved thousands or millions of rows of data thats gonna take time.
Then, the data gets returned back to the server and Tableau can then go about checking the data through the filters and finally can then think about rendering the sheets and bring up the dashboard.
All the while the user just sees

going round and round and round and round. And this is not great. I blame Google. We are so impatient now and waiting for more than a few seconds for a dashboard to load up, particuarly one that we might have to use often is a right miserable experience. So what can we do to get around this and make our users happy?
Extracts to the Rescue!
What’s great about a data extract is that it reduced all the chatter back and forth to the database. Instead, you simply ask for the data once and then keep a copy of it with your workbook/dashboard. Then every time someone looks at the published dashboard you are looking at the local copy of the data, which means fast interaction and happy users.
Ok, but what about the downsides to doing that? Well the major issue with an extract is that once you take the copy of the data in the extract it becomes stale. Any new data in the underlying database will not get reflected in the extract, until you refresh it. Now thats not too much of a problem as when you publish the extract you can inform Tableau Server to automatically refresh the extract at a certain frequency (which have been set-up by your lovely Server admins). So now we have a dashboard thats fast for the end user, is updating based on a set frequency and all is well in the world.
Well…..yes that’s true, but now, whenever one of your users loads up the dashboard, how do they know how old that data is, and that it’s not from a live connection, but an extract. Here’s what you can do. There are two automatic values that can be added to a worksheet, “Data Source Name” and “Data Update Time” What these do is take the name of the current data source that’s being used in the worksheet and makes it visible in your view.
Take this for example. Its a simple barchart with a simple title thats connected to a copy of superstore that i’ve called Superstore Extract, as its an extract.
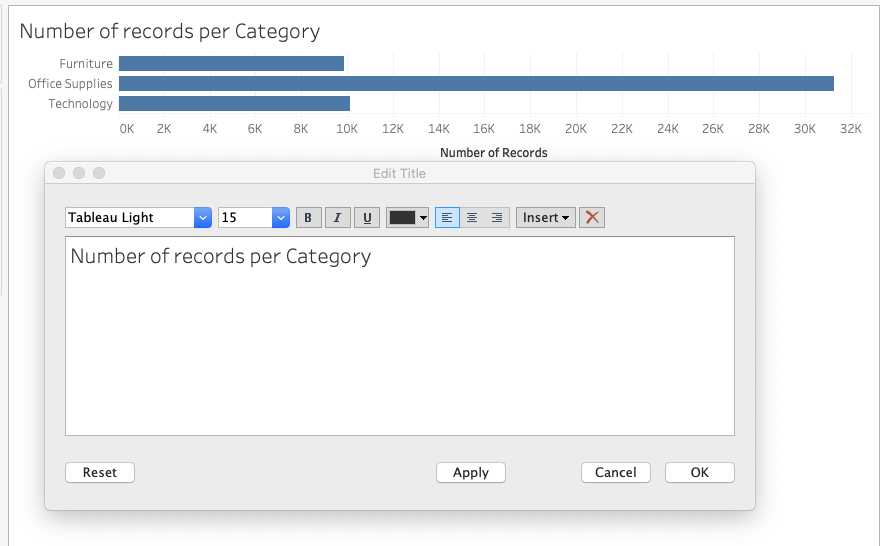
Now if i publish this my user has no idea that its from an an extract, but i want them to know that, and also when the data was extracts. So i can make use of the automatic function by clicking on Insert and adding the “Data Source Name” and “Data Update Time” to the title, add a little formatting and you get something like this
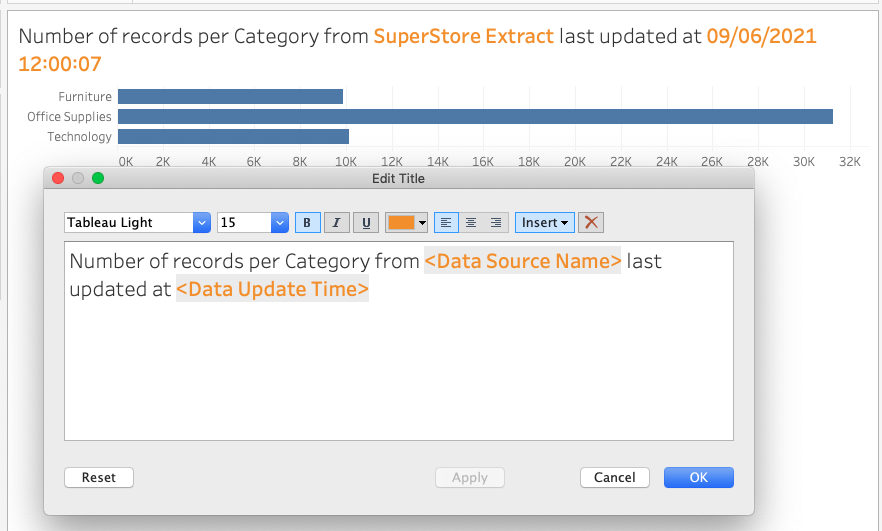
If this is now published to Server, and set-up to refresh on a schedule, whenever my user opens it up they will see where the data came from, that its an extract and when the extract last updated so they know that the data they are looking at is 4 hours old, or a week old, whatever.
This doesn’t just work for extracts, it can also be used for a live direct connection, in that case the data update time will be when the page was last refreshed as thats when the call to the database occurred.
By making use of “Data Source Name” and “Data Update Time” you can take advantage of the speed of extracts at the point of use and mitigate the issue of stale data by informing your users that what they are looking at is not live.


